As a Linux administrator, superuser, or beginner learning the ropes of the operating system ecosystem, it is essential to learn the Linux command line tweaks on how to deal with duplicate lines in a text file.
A common scenario that needs a quick and efficient approach to getting rid of these duplicate lines in a text file is when handling log files.
Log files are key/important in improving the user experience of Linux users through their computer-generated data. Such data can be translated as usage operations, activities, and patterns associated with a server, device, application, or system.
Handling such log files can be tedious due to the infinite number of information that continuously repeats itself. Therefore, sifting through such files is close to impossible.
Problem Statement
We will need a sample text file to reference throughout this article to make things more interesting and engaging:
$ sudo nano sample_file.txt
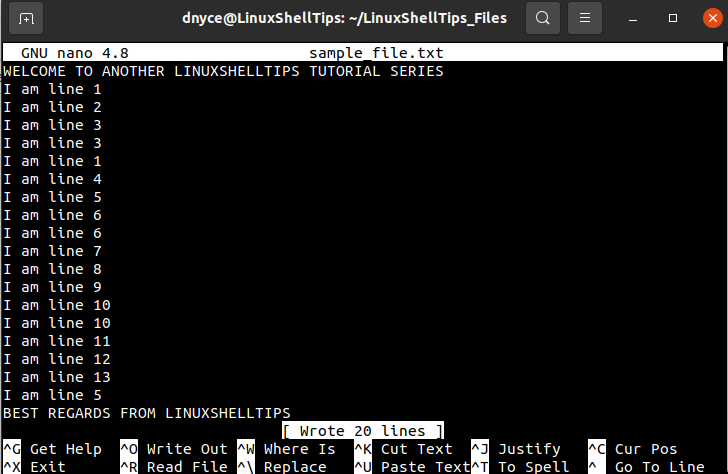
The above screen capture of the text file we just created contains some visibly repeated lines we will be trying to get rid of/delete. In a production-ready environment, such a file could be having thousands of lines making it difficult to get rid of the hidden duplicates.
Delete Duplicate Lines Using Sort and Uniq Commands
As per the man pages of these two GNU Coreutils commands, the sort command’s primary purpose is to sort lines within a text file while the uniq command’s primary purpose is to omit/report repeated lines within a targeted text file.
$ man sort $ man uniq
If we were to remove the duplicate lines from our text file using these two commands, we will run:
$ sort sample_file.txt | uniq
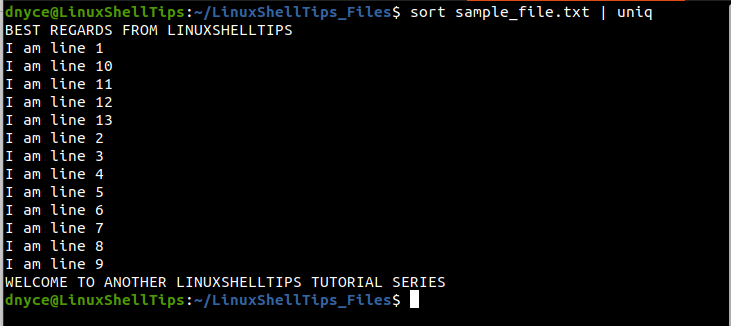
As expected, the duplicate entries have been deleted.
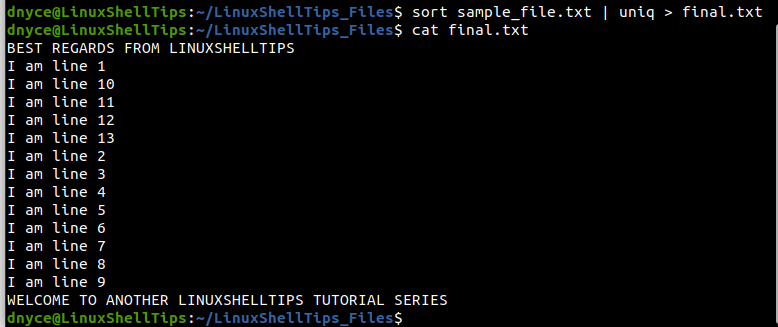
We can even redirect the output of the above commands to a file like final.txt.
$ sort sample_file.txt | uniq > final.txt
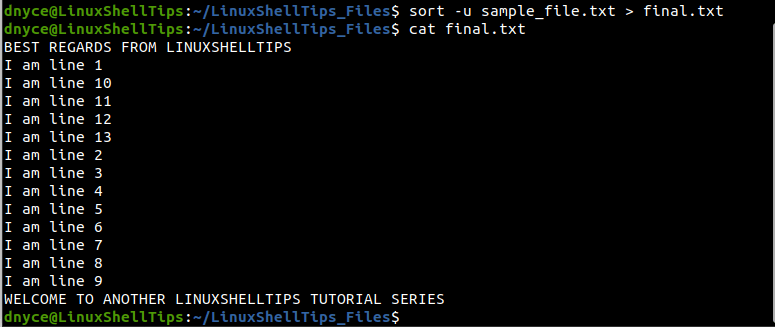
We can also use Linux’s sort command with the -u option to uniquely output the content of the file without duplicate lines.
$ sort -u sample_file.txt
To save the output to another file:
$ sort -u sample_file.txt > final.txt
How to Find Most Repeated Lines in File
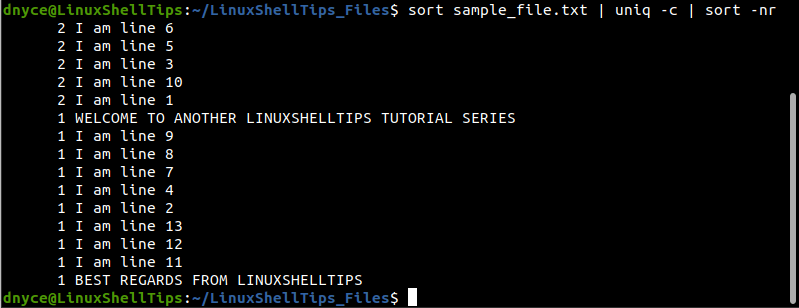
Sometimes you might be curious about identifying the most repeated lines in the text file. In such a case we will use two sort commands and a single uniq command.
$ sort sample_file.txt | uniq -c | sort -nr
Remove Duplicate Lines Using Awk Command
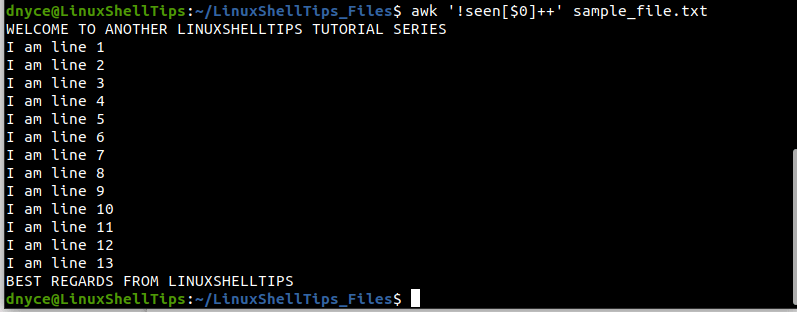
The awk command is part of the Free Software Foundation package and is primarily used for pattern scanning and processing language. Its approach gets rid of the duplicate lines on your text file without affecting its previous order.
$ awk '!seen[$0]++' sample_file.txt
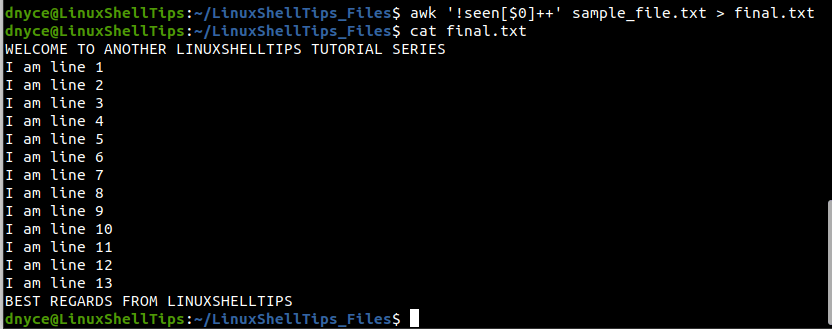
To save the output to another file:
$ awk '!seen[$0]++' sample_file.txt > final.txt
We have successfully learned how to remove duplicate lines in a text file from the Linux operating system terminal environment.